

REDMI Note 17 Pro评测:同档最强抗摔防水,2026年千元机市场的品质守门员
2026-07-14
本文从创建一个简单的SWT Tree Table开始,引入可重用的用户界面构件这个开发人员普遍关心的问题,然后分析Eclipse的用户界面的一些设计模式,循序渐进的向读者展示了如何设计实现一个精巧的高度可重用的TreeTable构件,最终通过增加一些扩展的功能显示了该构件强大的可扩展能力和灵活性。读者将能够了解到如何在SWT程序中设计实现可重用的构件,以减少重复的用户界面程序的工作量,降低因为需求变化所引起的风险和程序的维护成本。
1. 问题的起源
我们经常困惑于在不同的项目中重复的编写看上去很相似的代码,有时候会感觉自己只是一个体力劳动者,每天重复的编写着看上去很酷的程序。尤其是在用户界面编程中,拷贝粘贴成了家常便饭,那些迷人的SWT界面其实并没有给你带来什么热情。是的,你需要改变,让生活重新回复光彩,找到第一次写出 “HelloWord”的美好感觉。本文将向您展示如何实现灵活可扩展的SWT构件,本文所有的代码在Eclipse3.2.1平台上通过测试。
我们从这样一个问题开始,假设我们在一个基于Eclipse的RCP项目中,需要创建一个表格,用于显示员工信息。这个RCP项目会有很多个类似的表格,我们首先实现一个示例研究一下如何更好的设计用户界面。该表格是要显示一组按部门分组的员工,每个部门会有多个经理,每个经理管辖多个员工。因此我们要构建一个Tree Table,会有不同的列来显示不同的属性,而行的数据可能有3类:部门,经理,员工。我们设计这样的问题具有典型的代表性,Eclipse RCP应用中经常需要面对这样的情况。这是一个虚构的例子,与任何具体的应用无关,本文的代码只是作为示例使用。
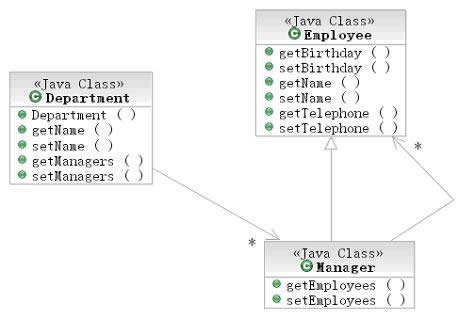
图1展示了模型部分的3个类:Department,Manager和Employee,详细的代码参见附件中的源代码。
图1:Tree Table示例的数据模型
构建一个简单的Tree Table
使用SWT和JFace的构件,我们可以很容易的构造出一个展示图1中的模型的Tree Table演示程序,该演示程序主要包含3个类:EmployeeContentProvider和 EmployeeLabelProvider,SimpleTestWindow。
如清单1所示,EmployeeContentProvider负责向TreeTable提供内容。
清单1:EmployeeContentProvider的代码。
| public class EmployeeContentProvider extends ArrayContentProvider implements ITreeContentProvider { public Object[] getChildren(Object parentElement) { if(parentElement instanceof Manager&((Manager)parentElement).getMembers()!=null) return ((Manager)parentElement).getMembers().toArray(); else if(parentElement instanceof Department) return ((Department)parentElement).getEmployees().toArray(); return new Object[0]; } public Object getParent(Object element) { return null; } public boolean hasChildren(Object element) { return getChildren(element).length>0; } } |
如清单2所示,EmployeeLabelProvider主要负责为每行的每一列显示Image和Text。
清单2:EmployeeLabelProvider的代码。
| public class EmployeeLabelProvider extends LabelProvider implements ITableLabelProvider{ public Image getColumnImage(Object element, int columnIndex) { return null; } public String getColumnText(Object element, int columnIndex) { if(element instanceof Department&& columnIndex ==0) return ((Department)element).getName(); else if(element instanceof Employee) { if(columnIndex ==0) return ((Employee)element).getName(); else if (columnIndex ==1) { if(element instanceof Manager) return "Manager"; else return "Employee"; } else if (columnIndex ==2) return ((Employee)element).getTelephone(); else if (columnIndex ==3) return ((Employee)element).getBirthday(); } return ""; } } |
清单3则展示了如何使用EmployeeContentProvider和EmployeeLabelProvider创建一个TreeTable的示例窗口。
清单3:SimpleTestWindow的代码。
| public class SimpleTestWindow extends ApplicationWindow { private TableTreeViewer ttv; public SimpleTestWindow() { super(null); } public void run() { setBlockOnOpen(true); open(); Display.getCurrent().dispose(); } protected void configureShell(Shell shell) { super.configureShell(shell); shell.setText("Simple Tree Table Test"); } protected Control createContents(Composite parent) { ttv = new TableTreeViewer(parent); ttv.getTableTree().setLayoutData(new GridData(GridData.FILL_BOTH)); ttv.setContentProvider(new EmployeeContentProvider()); ttv.setLabelProvider(new EmployeeLabelProvider()); ttv.setInput(TestDataGenerator.getTestDepartments()); #p#分页标题#e# // Set up the table Table table = ttv.getTableTree().getTable(); new TableColumn(table, SWT.LEFT).setText("Name"); new TableColumn(table, SWT.LEFT).setText("Job Title"); new TableColumn(table, SWT.RIGHT).setText("Phone"); new TableColumn(table, SWT.RIGHT).setText("Birthday"); for (int i = 0, n = table.getColumnCount(); i < n; i++) { table.getColumn(i).pack(); } table.setHeaderVisible(true); table.setLinesVisible(true); parent.pack(); ttv.reveal(ttv.getElementAt(0)); return ttv.getTableTree(); } public static void main(String[] args) { new SimpleTestWindow().run(); } } |
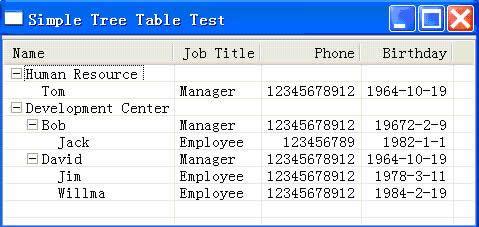
图2展示了运行SimpleTestWindow后所显示的TreeTable的效果,所有的代码我们已经打包进附件中的test_1.0.0.jar,模型部分代码见test.model包,测试代码见test.simple包。
图2:SimpleTestWindow的运行结果
这样的设计似乎非常的符合MVC设计模式(参见《设计模式:可复用面向对象软件的基础》),模型是Department数组,视图是一个 Tree,TableTreeViewer 的EmployeeLabelProvider和EmployeeContentProvider联合充当了控制器的角色,Department决定显示哪些东西,EmployeeLabelProvider决定如何显示(表格的内容和图标)。然而只要回顾以往项目的经验,我们很快就给自己提出了一些问题。
可重用问题的提出
虽然上面的示例中SWT的这种设计模式看上去很优美,然而经验使我们对EmployeeLabelProvider中 getColumnText方法中的复杂的条件判断还存在疑惑。难道只能这样无止境的判断下去吗?为什么不能直接的操纵每一列的数据呢?对于简单的需求,示例的说法相对容易,这么简洁的代码,你都不需要加任何的注释,然而一旦面对现实世界中纷繁复杂的业务系统,你的代码势必会迅速的膨胀,例如,仅对这个具体的表格来说:
如果有些行的某些列要求显示特殊的图标,你不得不在EmployeeLabelProvider 的getColumnImage方法中重复大量的判断;
如果调整了列之间的顺序,所有判断的地方都需要重新修改;
如果需要为每个不同的列增加不同的编辑功能(如text,Combo,Dialog),你也会增加很多相似的判断;
如果某些列被要求是可以被隐藏的…
如果希望给不同的列增加过滤显示的功能或者为某些列增加排序的功能…
如果某些特定的行或者列需要增加显示背景色…
如果某些行需要增加特定的右键菜单…
如果某些行可以打开特定的编辑器或者对话框…
好吧,这些事情是我们经常会遇见的,我打赌如果你就按部就班的把这些功能实现后你的ContentProvider和 LabelProvider中的代码一定混乱不堪,经过岁月的洗礼和需求的频繁变更,我们的代码迅速膨胀,就像Martin Fowler所说,到处散发出“臭味”,有经验的读者一定在项目中见过长达数千行的ContentProvider和LabelProvider类,这些类是如此的庞大以致于后期的维护和修改变得异常的困难。
何况,如果系统中存在数十个这样的不同的复杂的table,尽管你可以通过快速的拷贝,粘贴,重命名和简单的重构在几天内完成数十个表的工作,然而面对需求的变化,事情就变得越发的复杂,你不得不每天在需求的变化中,重复的修改这些数不清的ContentProvider和 LabelProvider,是谁让这个世界如此疯狂?我们一定经历过这样疯狂拷贝粘贴的年代,面对很多类似的表格,我们经常会重复的创建无数的 table,给他们增加很多相似的功能,当你沾沾自喜的数着自己一天又编写了多少个Java类,创建了多少个表格的时候,你是否想过,为什么这些Java 类看上去这样的相似,难道重复的拷贝相似的代码不能让你思考一些更好的办法吗?
是时候了,是时候我们重新开始,创建一个高度可重用的TreeTable构件了,这个构件还要具有很强的扩展能力。为什么要可重用?因为你会不止一次的用到它。为什么要扩展?因为它不一定完全满足你的需求。如果我们编写程序的时候时刻有这样的想法,我相信我们的程序一定会比以前提高很多,永远不要假定你的代码是封闭的,要时刻准备着被重用。
不要认为这样的想法是多余的,笔者对国内外多个大型业务系统有所接触(财务,税务,零售等),发现这些系统无一例外的构建在领域通用的框架之上,这些框架面对特定领域的问题的集合,提供了快速构建和灵活扩展的能力,其框架的可重用性非常强,业务开发人员可以开发很少的代码来构建完整的领域业务系统(极端的例子表明,可以不用编写代码就能生成定制的业务系统)。这些框架绝对不是一开始就被构建出来的,而是在实现多个类似业务系统过程中,逐渐的演化形成的,这些可定制的框架为软件公司带来了滚滚的利润,也为开发人员带来了很大的成就感。对于普通的程序员,只要我们坚持用可重用的眼光思考问题,就能得到提升。
首先,从小处看,我们应当保持代码的纯净,不能任何冗余的代码,冗余的即可重用。拷贝粘贴之余,只要我们坚持重构,在代码级别,我们能保持最大的重用性。更为重要的是,在保持了可重用性的同时,我们还集中了变化点,使得代码的维护变得更为容易。
其次,组件级别(UI上称为构件),只要用相似的功能,我们都能精简,将业务上或者技术上相似的功能封装成可重用的组件,你就会更上一层楼。
最高的境界就是框架层次上的,综合同领域内多个系统要面对的共同问题,构建一个可重用的框架,将会无数倍的降低我们构建类似系统的代价。#p#分页标题#e#
我们应当树立“编程序即是编框架”的观念,从小处入手,胸怀天下,随时随地重构,追求代码,组件和系统的可重用性,在实现可重用性的同时,正交的隔离变化点,集中的控制变化点,自然的实现系统的应变能力和可扩展能力。对于目前的问题,我们将对这个组件级别的重用问题具体分析,找出一种有效的解决方法。现在的代码看上去虽然不错,但是因为所有的逻辑集中在ContentProvider和LabelProvider中,导致对需求的变化无法有效隔离,每一次的需求改动波及面很大,并且结构混乱,代码中充满了 if else 或 switch 这样的嵌套重复判断。分析一下前面提出的种种需求,我们都是可以将这些需求区分为行的行为和列的行为。因此,我们需要将MVC模式细化,对于我们的 table而言,我们需要行控制器和列控制器,我们需要将类似的变化集中在某些地方,让这些细化的控制器各司其职。我们的目标是
1 创建一个高度可重用的TreeTable构件使得我们批量的构建TreeTable的时候可以节省大量的工作;
2 该构件能够精确控制行和列的显示以及行为;
3 具有高度的可扩展性,便于增加新的功能而不破坏原有的结构。
那么如何开始呢?你一定有过类似的经验,当你遇到无法解决的问题的时候,你会去研究一些开源的软件,开源软件的无私精神使你能够了解到世界上最顶级的代码,学习和研究这些代码会让你获益匪浅。所以让我们从Eclipse中的一些用户界面设计模式开始吧。
2. 从Eclipse中的用户界面设计模式开始
我们将在这一部分研究Eclipse的一些用户界面设计模式,从而了解到如何使用隔离关注的方法精确控制TreeTable 的行和列。
实现列控制器的IField设计模式
现在我们就要寻找一种SWT的设计模式,这个模式要能精确的控制Table中的每一列的行为。没有问题,Eclipse的内部就使用这样一种设计模式,可以分散控制每个table的每一列的显示。研究Eclipse但源码和API文档,我们很快就发现,ProblemView这个view中引用了很多的IField的接口,当看到图3中IField接口的方法时,我们就了解到这个正是用来控制 Table中的每一列的列控制器。
图3: IField接口的方法
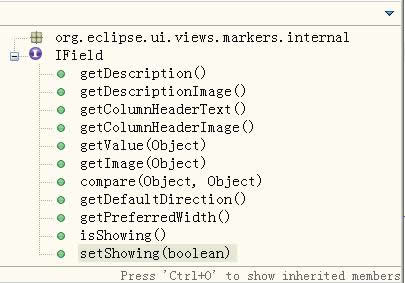
IField接口作为Table的列控制器,能够控制每列的列名,列头(Header)的icon,列头的tooltip,列头的 tooltip的icon,每个 cell 的 Image 和 Text(getValue方法),并支持cell之间的比较,可以用于排序,我们将稍后详细的介绍该模式的运行原理。
看上去这个是很不错的框架,遗憾的是在Eclipse中这种设计模式似乎并没有流行起来,从源码中我们就可以看见 LogView 就是完全按照我们第一部分的方法纯手工写就的。对于一个简单的 TreeTable,采用简单的方法做没有任何问题。问题在于,在应用系统中,你很难保证需求不会变更,功能不会膨胀,尤其在像在以表格展现为主的RCP 应用中,TreeTable的编程 将成为你日常生活的一部分,此时创建一个高度灵活和可重用的TreeTable构件将显得异常重要。
因此我们将使用这种模式来构建我们的TreeTable,我们只要在LabelProvider中调用到这些IField的方法,就能精确控制Table的列,那么,如何控制表格行的行为呢?
可用于行控制器的IWorkbenchAdapter接口
IWorkBenchAdapter是Eclipse JDT中经常用到的一个接口,该接口通常用于不同类型的节点在树中的显示,如我们常见的Java包浏览器,从接口以及API文档中我们可以看到它的层次关系。图4的类阶层结构展示了Java包浏览器如何使用IWorkBenchAdapter对节点分类显示的。
图4:IWorkBenchAdapter 的类阶层结构
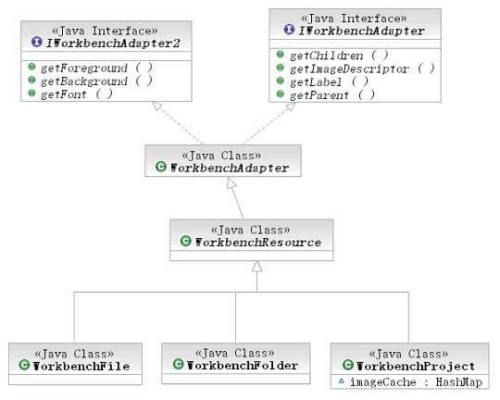
图4中可以明显看见WorkBenchAdapter类会将每个对象(文件,文件夹,项目)适配包浏览器中的树节点,如果我们想象树中的每个节点代表每一行数据(一个只有一列的表),那么这样一种设计模式就是完全按行来控制的行控制器设计模式,我们可以为不同类型的行数据创建不同的适配器,精确控制这些数据的表现形式,如背景色、前景色、字体等,只要你愿意,还可以增加一些菜单或者打开编辑器等丰富的功能。本文将借鉴Eclipse的这一模式来设计TreeTable的行控制功能。图4显示了对File,Folder和Project这三种不同类型的数据做不同的控制,我们的构件中,将能够根据对象而不是类型做更为精确的控制。本文将参考WorkBenchAdapter的设计实现TreeTable的行控制器。
3.创建可重用的TreeTable构件
基于以上的研究,我们实现了一个高度可重用的TreeTable构件,限于篇幅,我们只实现了能够说明问题的最关键的功能。
使用IField实现列控制
为了便于说明问题我们创建了一个简单版本的IField接口,参见图5。
图5:简化后的IField接口
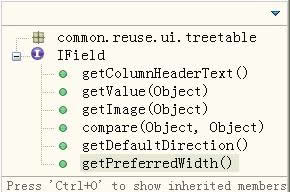
同时实现一个通用的TreeTableLabelProvider类,它使用IField接口控制列的行为。
清单4:TreeTableLabelProvider的代码
| public class TreeTableLabelProvider extends LabelProvider implements ITableLabelProvider { private IField[] fields; public TreeTableLabelProvider(IField[] fields) { this.fields = fields; } public Image getColumnImage(Object element, int columnIndex) { if (element == null || fields == null || columnIndex < 0 || columnIndex >= fields.length || fields[columnIndex] == null) { return null; } return fields[columnIndex].getImage(element); } #p#分页标题#e# public String getColumnText(Object element, int columnIndex) { if (element == null || fields[columnIndex] == null || fields == null || columnIndex < 0 || columnIndex > fields.length) { return ""; } return fields[columnIndex].getValue(element); } } |
我们还实现了一个TreeTableViewer,如清单5所示,TreeTableViewer会根据IField来创建TreeTable的column。
清单5:TreeTableViewer的代码
| public class TreeTableViewer extends CheckboxTreeViewer { private IField[] fields; public TreeTableViewer(Tree tree,IField[] fields, ITreeTableAdapterFactory adapterFactory) { super(tree); this.fields =fields; super.setContentProvider(new TreeTableContentProvider(adapterFactory)); super.setLabelProvider(new TreeTableLabelProvider(fields)); createColumns(); } public void setTableInput(Object[] input) { super.setInput(input); } protected void createColumns() { IField[] fields = getFields(); for (int i = 0; i < fields.length; i++) { if (fields[i] != null) { TreeColumn tc = new TreeColumn(getTree(), SWT.NONE); tc.setText(fields[i].getColumnHeaderText()); tc.setWidth(fields[i].getPreferredWidth()); tc.setData(fields[i]); } } } public IField[] getFields() { return fields; } } |
TreeTableViewer 的构造函数中需要一个 ITreeTableAdapterFactory作为参数,这是一个适配器工厂(参见《设计模式:可复用面向对象软件的基础》中的适配器工厂模式),主要根据每一行的对象获取到相应的ITreeTableAdapter作为行控制器。这个控制器主要用在了默认的 TreeTableContentProvider中,详见清单6。
清单6:TreeTableContentProvider的代码
| public class TreeTableContentProvider extends ArrayContentProvider implements ITreeContentProvider { private ITreeTableAdapterFactory adapterfactory; public TreeTableContentProvider(ITreeTableAdapterFactory adapterfactory) { this.adapterfactory = adapterfactory; } public Object[] getChildren(Object parentElement) { return ((ITreeTableAdapter) adapterfactory.getAdapter(parentElement)) .getChildren(parentElement); } public Object getParent(Object element) { return ((ITreeTableAdapter) adapterfactory.getAdapter(element)) .getParent(element); } public boolean hasChildren(Object element) { return getChildren(element).length > 0; } |
使用ITreeTableAdapter实现行控制
ITreeTableAdapter的接口很简单,它参考了IworkbenchAdapter接口的设计,实现了TreeTable中的行逻辑的控制,详见清单7。
清单7:ITreeTableAdapter的代码
| public interface ITreeTableAdapter { public Object[] getChildren(Object o); public Object getParent(Object o); public Color getBackgroundColor(Object element); } |
为什么TreeTableContentProvider一定需要一个ITreeTableAdapterFactory来作为参数构造呢? 我们考虑一些复杂的情况,一个Table的行,可能会有多种类型的控制方式(还记得第二部分的IWorkbenchAdapter有三个实现吗?)因此我们会为每种类型的行数据创建一个特殊的行控制器,ITreeTableAdapterFactory可以为ContentProvider提供多个 ITreeTableAdapter以实现不同类别的行数据的控制逻辑可以单独在一个类中实现,有效的隔离了代码,使得应用程序结构比较清晰。如果你的程序足够简单,你只需要实现一个ITreeTableAdapter,然后使用FixedTreeTableAdapterFactory就可以了,如清单 8所示,FixedTreeTableAdapterFactory的接口非常简单,就是返回一个固定的适配器。
清单8:FixedTreeTableAdapterFactory的代码
| public class FixedTreeTableAdapterFactory implements ITreeTableAdapterFactory{ private ITreeTableAdapter adapter; public FixedTreeTableAdapterFactory(ITreeTableAdapter adapter){ this.adapter=adapter; } public ITreeTableAdapter getAdapter(Object treeitemdata) { return adapter; } } |
通常的适配器模式,被适配的对象需要实现IAdaptable的接口,显然这里我们不能采用侵入方式的adapter模式。我们的对象模型是纯净的对象模型,因此我们需要适配器工厂模式,通过工厂取得适配器对象。根据对象获取适配器可以更为精确的控制你的程序,例如我们的示例中,如果不同的部门在table中的行为需要严格控制,或者出生年龄在一定区间的员工需要特殊显示,那么我们可以为每种有特定需求的行数据对象建一个适配器,根据判断行数据的属性来找到具体的适配器。相比较IWorkBenchAdapter, ITreeTableAdapter做了一些修改,不需要提供Label和Image,我们的ITreeTableAdapter更关注行的控制。 TreeTableContentProvider和ITreeTableAdapter的关系详见图6所示。#p#分页标题#e#
4.使用TreeTable构件的示例
基于以上实现的TreeTable构件,我们如果要实现第一部分的示例界面,需要做那些工作呢?首先我们要实现类派生于 AbstractField的类充当表的4个列控制器,每个Field的getColumnHeaderText就控制该列的显示,我们依次实现了 NameField、TitleField、PhoneField和BirthField。读者可以参考NameField的代码,详细代码请见附件。
清单10:NameField的代码
| public class NameField extends AbstractField { public String getColumnHeaderText() { return "Name"; } public String getValue(Object object ) { if(object instanceof Employee) return ((Employee)object).getName(); else if(object instanceof Department) return ((Department)object).getName(); else return ""; } } |
同时我们需要实现一个适配器EmployeeTreeTableAdapter来控制TreeTable行的行为,这里因为行之间的行为比较简单,我们只要使用一个适配器就能应付需求,如果有更复杂的需求,我们可以轻易的使用新的适配器,来扩展TreeTable行控制能力。清单11给出 EmployeeTreeTableAdapter的代码。
清单11: EmployeeTreeTableAdapter的代码
| public class EmployeeTreeTableAdapter extends DefaultTreeTableAdapter { public static EmployeeTreeTableAdapter instance=new EmployeeTreeTableAdapter(); private EmployeeTreeTableAdapter(){} public Object[] getChildren(Object parentElement) { if(parentElement instanceof Department&&((Department)parentElement).getManagers()!=null) return ((Department)parentElement).getManagers().toArray(); else if(parentElement instanceof Manager&&((Manager)parentElement).getEmployees()!=null) return ((Manager)parentElement).getEmployees().toArray(); else return new Object[0]; } } |
注意,这里我们返回new Object[0] 而不是null,可以避免引起不必要的判空。 此时,测试代码也变得简单多了(说明实际的开发代码将更为简单),如清单12所示。
清单12:TreeTable的测试代码
| public class TestWindow extends ApplicationWindow { public TestWindow() { super(null); } public void run() { setBlockOnOpen(true); open(); Display.getCurrent().dispose(); } protected void configureShell(Shell shell) { super.configureShell(shell); shell.setText("Reusable Tree Table Test"); } protected Control createContents(Composite parent) { IField[] fields = new IField[] { new NameField(), new TitleField(), new PhoneField(), new BirthField() }; TreeTable treeTable= new TreeTable(parent, SWT.BORDER ,fields, new FixedTreeTableAdapterFactory(EmployeeTreeTableAdapter.instance) ); treeTable.setInput(TestDataGenerator.getTestDepartments()); return treeTable.getTree(); } public static void main(String[] args) { new TestWindow().run(); } } |
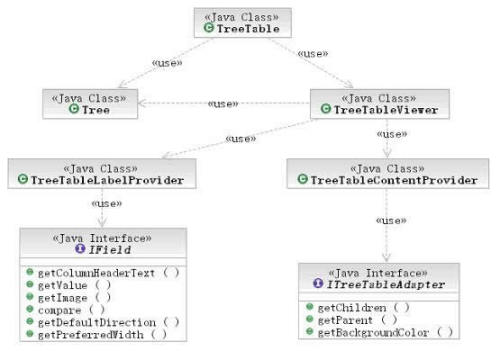
TestWindow的运行结果和图2完全相同。这里的TreeTable构件,使用非常简单,你可以像使用一个普通的SWT构件一样使用它,并且TreeTable的实现使用了一系列细粒度的控制器,读者可以参考图8的类图。
图8:TestWindow中TreeTable的构成
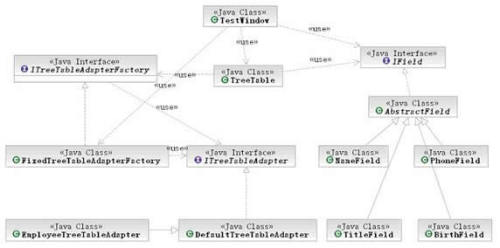
从图8中我们可以看出,虽然我们新建了5个类,多于在第一部分创建的2个类,但是很好的隔离了行和每个列的控制,结构具有松散耦合的特点,具有很好的扩展性,我们将在第四部分演示如何扩展。本部分的示例代码参见附件中的test_1.0.0.jar。这种细粒度的控制可以完全的分散程序的功能,也就大大简化了代码的结构,清晰易读,具有自解释的功能,大量的细粒度的类和方法,本身就是最好的注释,这样的代码具有很强的可维护性,在大规模的项目中,还有助于快速定位和解决问题。
也许读者已经注意到EmployeeTreeTableAdapter中的判断代码,如果情况再复杂一点,我们就需要为三种数据类型分别构建3 个Adapter,这里我们只使用一个,把它简单化处理了。这样的判断不能避免,但是我们可以通过将判断转移到适配器工厂,可以只要判断一次,将不同的逻辑分散于不同的适配器中,避免重复的判断代码,重复的代码维护起来很不方便。
有经验读者可能会问,既然如此强调可重用性,为什么不为TreeTable建立一些扩展点,用添加扩展的方法去控制该实例的行为呢?就本文的示例而言,我们的考虑是这样的:#p#分页标题#e#
1 Eclipse的PDE中扩展编辑器功能较弱,基本无法进行有效的语法检查和正确性校验(初学者也许有过在plugin.xml里面写错一个字母而浪费半天时间调试的经历)。
2 对于这样一个具体的构件,用扩展点来做就未免有点问题扩大化,将会牺牲了程序的简洁和优美,降低开发速度。
3 扩展点虽然可以实现松耦合,但是隔断了代码之间的关联关系,为程序的编写带来不便。
实际上,Eclipse程序员会有一种倾向,有人会习惯而自然的为所有可重用的组件添加扩展点,期望用扩展的方法来重用代码。从而造成扩展点过多,程序结构过于复杂。而我们认为最适合的就是最好的,扩展点的约束和控制条件都相对较弱,过量的使用扩展点和扩展会破坏程序的连贯性,对开发过程反而有害。因此我们不建议在Eclipse项目中滥用扩展点,Eclipse的扩展点机制可以增强程序的整体可延伸性,但是细粒度的局部的构件,采用面向对象的传统方法实现重用,无论从代码的可读性和开发的效率来看,都是非常适合的。
5.增加TreeTable构件的功能
现在我们将向您展示该构件超强的扩展能力,我们将轻松的实现TreeTable的列排序的功能,然后为特定的行增加背景色。上文的 TreeTable实现中,相关的接口都已经具备了,这里我们将实现这些扩展能力。限于篇幅,第一部分中所提到的很多扩展的功能,有兴趣的读者可以参考我们的实现完成。
增加列排序功能
我们的列排序的接口已经提供了对排序的基本支持,详见图9。
图9:IField支持排序的接口
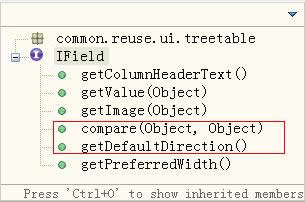
compare方法将返回两条数据(Table中的两行在此列的Cell的值)比较后的值来决定这两行的顺序。 getDefaultDirection方法将表示该列的排序是升序还是降序。由于设计上的精巧,我们不需要为每个IField实现该接口,我们只需要在 AbstractField中实现这两个方法,代码参见清单13,有特殊需要的子类可以重载它们。
清单13:AbstractField中支持排序的方法
| public int compare(Object obj1, Object obj2) { if (obj1 == null || obj2 == null) { return 0; } if (getValue(obj1) != null&&getValue(obj2)!=null) return getValue(obj1).compareTo(getValue(obj2)); else return 0; } public int getDefaultDirection() { return 0; } |
TreeTableViewer中需要添加清单14中的代码。
清单14:TreeTableViewer中增加的代码
| private TreeTableSorter tableSorter; protected void initSorters() { if (fields.length > 0) { tableSorter = new TreeTableSorter(fields[0]); setSorter(tableSorter); } TreeColumn[] columns = getTree().getColumns(); columns[0].addSelectionListener(new RowSelectionListener()); } private class RowSelectionListener extends SelectionAdapter { public void widgetSelected(SelectionEvent e) { TreeColumn column = (TreeColumn) e.widget; IField sortField = (IField) column.getData(); Tree tree = column.getParent(); tree.setSortColumn(column); tableSorter.setSortField(sortField); int direction = tableSorter.getSortDirection(); if (direction == TreeTableSorter.ASCENDING) tree.setSortDirection(SWT.UP); else tree.setSortDirection(SWT.DOWN); refresh(); } } |
然后再新建一个TreeTableSorter 类,代码如清单15所示。
清单15:新建的TreeTableSorter
| public class TreeTableSorter extends ViewerSorter { public static final int ASCENDING = 1; public static final int DESCENDING = -1; private IField field; private int sortDirection = ASCENDING; public TreeTableSorter(IField field) { super(); this.field = field; } public void setSortField(IField sortField) { if (this.field == sortField) sortDirection *= -1; else { sortDirection = ASCENDING; this.field = sortField; } } public IField getSortField() { return field; } public int getSortDirection() { return sortDirection; } public void setSortDirection(int sortDirection) { this.sortDirection = sortDirection; } public int category(Object element) { return super.category(element); } public int compare(Viewer viewer, Object e1, Object e2) { if (sortDirection == ASCENDING) return field.compare(e1, e2); return field.compare(e2, e1); } public boolean isSorterProperty(Object element, String property) { return super.isSorterProperty(element, property); } public void sort(Viewer viewer, Object[] elements) { super.sort(viewer, elements); } } |
在TreeTableSorter的compare方法里,我们轻松的调用IField的compare方法就完成了行数据在该列的排序。有过 table排序经验的读者一定有过在比较方法区分每一列的数据进行比较,不得不重复的编写那些烦人的“if…else…”代码。而在我们的 TreeTableSorter中,每一列的IField可以自己控制排序算法,因此不需要重复针对不同的列做判断,我们只需要为需要排序的列添加代码中的RowSelectionListener就可以使该列具备排序功能(当然在TreeTable情况下,最好只对第一列排序)。需要添加的代码形如: columns[i].addSelectionListener(new RowSelectionListener());
请注意我们的TreeTableSorter是一劳永逸的方法,当你的构件增加了排序的功能后,你只需要为每一列添加 RowSelectionListener就可以自动的实现该列的排序。更为复杂的情况下,你可以为每个列增加一个属性,来决定该列是否可以排序,这样你甚至都不需要对Table本身做任何修改就可以控制每列的排序能力。
此时运行测试窗口,点击“Name”的表头,行数据,将能按顺序排序,这里我们只对树的第一层进行排序,效果见图10和图11。
图10:按部门名字升序排列
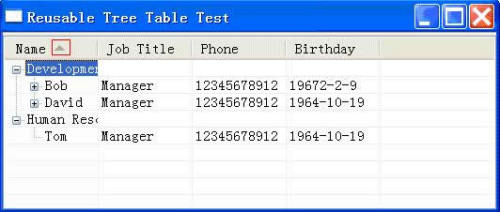
图11:按部门名字降序排列
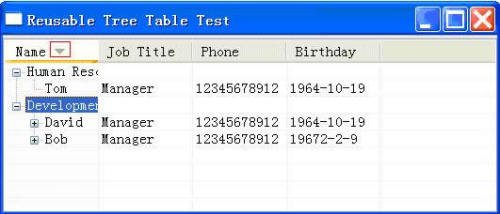
图6:TreeTableContentProvider和ITreeTableAdapter的关系
如图6, 在这样的设计结构下,所有的适配器被适配器工厂统一管理,一旦行数据的模型发生改变,系统只需要增加相应的适配器就可以了,系统的结构完全是开放的,可扩展的,并且这种扩展关系是非侵入的,不会造成模型或者视图的代码膨胀。
完整的TreeTable构件
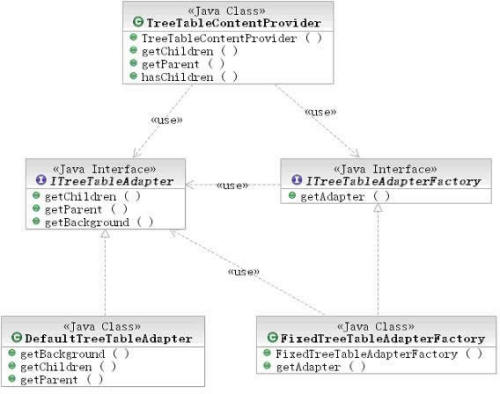
现在,基于以上的设计和分析,我们实现了TreeTable构件,如图7所示,该构件包装了一个使用TableLayout的Tree构件,在该tree的viewer中,我们使用到了特殊的ContentProvider和LabelProvider。如清单9所示,TreeTable使用 IField控制table的列行为,使用ITreeTableAdapter控制行行为。虽然看起来比原来的简单实现复杂,但是结构清晰,便于维护和升级,我们可以轻易的增加新的功能而不会破坏良好的程序结构,我们将在第4部分向读者展示这一点。图7:TreeTable构件的类图
图7:TreeTable构件的类图
清单9:TreeTable的代码
| public class TreeTable { protected Composite parent; protected Tree tree; protected TreeTableViewer treeViewer; protected ViewForm form; private ITreeTableAdapterFactory adapterFactory; public TreeTable( Composite parent,int style,IField[] fields, ITreeTableAdapterFactory adapterFactory) { this.parent=parent; this.adapterFactory=adapterFactory; initTable( parent , style); treeViewer= new TreeTableViewer(tree,fields,adapterFactory); form.setContent(tree); } private void initTable( Composite parent , int style) { form = new ViewForm(parent, style); form.setLayout(new FillLayout()); form.setBorderVisible(false); form.marginHeight = 0; form.marginWidth = 0; GridData gd = new GridData(SWT.FILL,SWT.FILL,true,true); form.setLayoutData(gd); initTree(form,style); } private void initTree(Composite parent, int style) { tree=new Tree(parent,style); tree.setHeaderVisible(true); tree.setLinesVisible(true); tree.setEnabled(true); tree.setLayout(new TableLayout()); } public void setInput(Object[] inputs){ if(treeViewer!=null) treeViewer.setTableInput(inputs); } public Tree getTree() { return tree; } public TreeTableViewer getTreeViewer() { return treeViewer; } } |
本部分的所有代码我们已经打包于附件中的common.reuse.ui_1.0.0.jar
增加行背景色功能
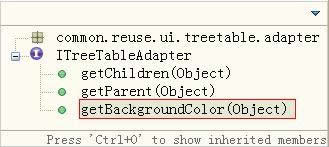
我们还记得ITreeTableAdapter接口的方法getBackgroundColor,如图12所示,该方法就是要返回特定数据行的背景色,目前为止,EmployeeTreeTableAdapter的该方法没有实现具体的逻辑,我们将这里演示如何给特定的行数据增加背景色, 我们需要给EmployeeTreeTableAdapter 增加清单16中的代码。。
图12:ITreeTableAdapter的接口
清单16:EmployeeTreeTableAdapter中增加的代码
| private Color depColor=new Color(null, 255,00,00); public Color getBackgroundColor(Object element) { if(element instanceof Department) return depColor; else return null; } |
此外还需要在TreeTable中的setInput方法中做一些修改,代码见清单17。#p#分页标题#e#
清单17:TreeTable的代码变更
| public void setInput(Object[] inputs){ if(treeViewer!=null) treeViewer.setTableInput(inputs); initColumnBGColorProperty(); } private void initColumnBGColorProperty() { TreeItem[] items = getTree().getItems(); for (int i = 0; i < items.length; i++) { TreeItem item = items[i]; Color rowItemBGColr =adapterFactory.getAdapter(item.getData()).getBackgroundColor(item.getData()); if(rowItemBGColr!=null) item.setBackground(rowItemBGColr); } } |
此时运行测试窗口,我们成功的给部门行增加了红色背景色,效果见图13。读者可以预料到,一旦需求发生变化,例如需要给某个特定的雇员以特别的颜色显色,我们可以快速的定位到EmployeeTreeTableAdapter,简单的修改getBackgroundColor方法就可以,可见细粒度的控制可以快速的定位代码,灵活的响应变化。
图13:部门行增加背景色的界面效果
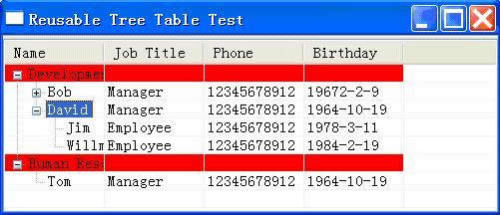
因此可以了解到,在这样一种体系结构下,我们的代码可以很容易的扩展去精确控制TreeTable的行为,并且在扩展之后仍然保持很清晰,简洁的体系结构。由于我们集中的控制各个方面的变化,我们的扩展是正交的,功能上互相没有影响,代码上也没有重复。如果此时我们还在使用第一部分的代码,如果你有多个TreeTable的实例,恐怕免不了又要重复的拷贝很多的代码。我们还可以给TreeTable增加了编辑、过滤、菜单、列顺序设置、列隐藏和平面显示等功能,可以在项目中大大的提高开发的效率,限于篇幅,这里不加赘述,有兴趣的读者可以参考本文的内容自行实现。
6. 总结
本文向读者展示了如何编写可重用的用户构件界面,并提供了一个TreeTable的例子,本文的读者可以根据需要自由的扩展,创建功能更为丰富的TreeTable构件。在大型的RCP项目中,系统会中有很多的对象模型,用户界面可能有数十个表格。使用这种可重用的构件,我们可以快速的创建复杂的界面,降低工作量。并且由于设计上的灵活性,可以极大的降低代码的维护成本和需求变更引发的工作量。良好的可扩展性将会使你的应用时刻保持清晰的架构,能够快速响应模型的变化。
通过本文的一些实践,读者也可以思考一下其他方面的可重用性设计,如果你热爱程序员这个工作,就应当不懈的坚持下去,最终期望能够实现“厚集薄发”,将越来越多的冗余代码重构成精简的可重用代码,提高程序质量和可维护性。我们的代码应该看上去和机器生成的一样整齐和简洁,不需要太多额外的注释 (细粒度的类名和方法名都是自解释的),每一个类和方法的都是那样的优美、短小而精悍,系统的结构清晰而灵活,不再害怕变化,即使经过很久的演进依然保持良好的结构和旺盛的生命力。这也是我们作为程序员的共同的目标。
评论 {{userinfo.comments}}
{{child.content}}

 {{money}}元
{{money}}元




{{question.question}}
提交







































